Web App
Sviluppo Web Application: best pratice
Il nostro know how nel progettare una Web Application
Una panoramica sull’architettura delle web application
L’architettura di una web application presenta un layout con tutti i componenti software (come database, applicazioni e middleware) e il modo in cui interagiscono tra loro. Definisce il modo in cui i dati vengono consegnati tramite il protocollo HTTP e garantisce che il server lato frontend ed il server backend possano dialogare tra loro. Inoltre, garantisce la presenza di dati validi in tutte le richieste degli utenti. Crea e gestisce i record, fornendo accesso e autenticazione basati sui permessi. La scelta del design giusto permetterà la crescita dell’azienda, l’affidabilità e l’interoperabilità e le esigenze informatiche future. Per questo motivo, è importante comprendere i componenti che costituiscono l’architettura delle applicazioni web.
Componenti dell’architettura delle web app
In generale, l’architettura di un’applicazione basata sul web comprende 3 componenti fondamentali:
- Browser Web: il browser o il componente lato client o il componente front-end è il componente chiave che interagisce con l’utente, riceve gli input e gestisce la logica di presentazione controllando le interazioni dell’utente con l’applicazione. Se necessario, gli input dell’utente vengono anche convalidati.
- Server web: Il server web, noto anche come componente di backend o componente lato server, gestisce la logica aziendale ed elabora le richieste dell’utente indirizzandole al componente giusto e gestisce le operazioni dell’intera applicazione. Può eseguire e supervisionare le richieste provenienti da un’ampia gamma di client.
- Database server: Il server del database fornisce i dati necessari all’applicazione. Gestisce le attività relative ai dati. In un’architettura a più livelli, i server di database possono gestire la logica aziendale con l’aiuto di procedure memorizzate.
Che cos’è un’architettura a 3 livelli (3-tier level)?
In un’architettura tradizionale a due livelli, ci sono due componenti: il sistema lato client o l’interfaccia utente e il sistema backend, che di solito è un server di database. In questo caso, la logica aziendale è incorporata nell’interfaccia utente o nel server di database. L’aspetto negativo dell’architettura a due livelli è che con l’aumentare del numero di utenti, le prestazioni diminuiscono. Inoltre, l’interazione diretta tra il database e il dispositivo dell’utente solleva anche alcuni problemi di sicurezza. I sistemi di prenotazione ferroviaria, per esempio, e i sistemi di gestione dei contenuti sono un paio di applicazioni che di solito vengono realizzate con questa architettura.
Schema di una architettura a 3 livelli
L’architettura a 3 livelli introduce un terzo livello chiamato “applicazione”:
- Livello di presentazione / Livello client
- Livello di applicazione / Livello di business
- Livello dati
Architettura delle web application standard
In questo modello, i server intermedi ricevono le richieste dei clients e le elaborano coordinandosi con i server subordinati che applicano la logica aziendale. La comunicazione tra il client e il database è gestita dal livello applicativo intermedio, consentendo così ai client di accedere ai dati da diverse soluzioni DBMS. L’architettura a 3 livelli è più sicura perché il client non accede direttamente ai dati. La possibilità di distribuire i server applicativi su più macchine offre una maggiore scalabilità, migliori prestazioni e un migliore riutilizzo. Si può scalare orizzontalmente scalando ogni elemento in modo indipendente. È possibile astrarre il core business dal server di database per eseguire in modo efficiente il bilanciamento del carico. L’integrità dei dati è migliorata perché tutti i dati passano attraverso il server applicativo che decide come accedere ai dati e da chi. Per questo motivo, un cambio di gestione è facile e conveniente. Il livello client può essere un “thin-client”, riducendo così i costi dell’hardware. Questo modello modulare consente di modificare un singolo livello senza influenzare i componenti rimanenti.
Livello di applicazione: Server Web
Che cos’è un server web? In poche parole, un server web gestisce uno o più siti web o web app. Il server web utilizza l’HyperText Transfer Protocol (HTTP) e altri protocolli per ascoltare le richieste degli utenti tramite un browser. Le elabora applicando la logica aziendale e consegnando il contenuto richiesto all’utente finale.
Un server Web può essere un dispositivo hardware o un programma software.
Server Web hardware: è un dispositivo informatico connesso a Internet che contiene il software del server web e i componenti della web application, come immagini, documenti HTML, file JS e fogli di stile CSS.
Server web software: è un software che è in grado di comprende le URL e i protocolli HTTP. Gli utenti possono accedervi tramite nomi di dominio per ricevere i contenuti richiesti.
Mentre un server web statico consegna al browser il contenuto così com’è, un server web dinamico aggiorna i dati prima di consegnarli al browser.
Livelli dell’architettura di una web application moderna
La costruzione di una moderna architettura di una web application a livelli aiuta a identificare il ruolo di ogni componente di un’applicazione e ad apportare facilmente modifiche al livello corrispondente senza influire sull’intera applicazione. Consente di scrivere, eseguire il debug, gestire e riutilizzare facilmente il codice.
I tre livelli dell’architettura di una web app:
- Livello di presentazione / Livello client
- Livello dell’applicazione / Livello della logica aziendale
- Livello dati

Apache web server
Apache è un popolare server web open-source della Apache Software Foundation. È stato sviluppato da Robert McCool in C e XML nel 1995. Apache si basa su un modello orientato ai processi, in cui ogni richiesta comporta la creazione di un nuovo thread. Il design modulare di Apache consente di scalare facilmente le singole risorse. Con una configurazione minima è possibile gestire anche un traffico di grandi dimensioni. Funziona su ambienti MacOS, Windows e Linux. Tuttavia, Linux è l’ambiente preferito per Apache.
Mentre per elaborare i contenuti statici utilizza un file system, i contenuti dinamici vengono elaborati all’interno del server. Utilizzando i file .htaccess è possibile eseguire ulteriori configurazioni delle impostazioni del server. La sicurezza è buona. Offre supporto tramite IRC, Stack Overflow e mailing list.
I vantaggi di Apache Server:
- Apache è open-source e si può ottenerlo gratuitamente
- Il codice, personalizzabile, può essere adattato alle necessità
- Esiste la possibilità di aggiungere altre caratteristiche e moduli per migliorare le funzioni
- E’ altamente affidabile e dalle prestazioni eccellenti
- E’ semplice da installare
- La registrazione delle modifiche è immediata
- Può essere eseguito su ogni sistema operativo
- Può essere mantenuto e aggiornato attivamente da una comunità
- E’ un Server Web altamente flessibile
- La documentazione è molto ampia
Gli svantaggi di Apache Server:
- La possibilità di modificare la configurazione può comportare problemi di sicurezza in quanto si possono aprire porte insicure.
- La personalizzazione può comportare a bug ed errori.
- Il debug comporta un consumo di tempo e risorse
- È necessaria una rigorosa politica di aggiornamento che deve essere effettuata a intervalli regolari.
- Necessita il riconoscimento e la disattivazione di servizi e moduli indesiderati
- Presenta problemi di prestazioni su siti web estremamente trafficati.
Livello di presentazione: Componente lato client (front-end)
Il componente lato client dell’architettura di una web app consente agli utenti di interagire con il server e con il servizio di backend tramite un browser. Il codice risiede nel browser, riceve le richieste e presenta all’utente le informazioni richieste. È qui che entrano in gioco il design UI/UX, le dashboard, le notifiche, le impostazioni di configurazione, il layout e gli elementi interattivi.
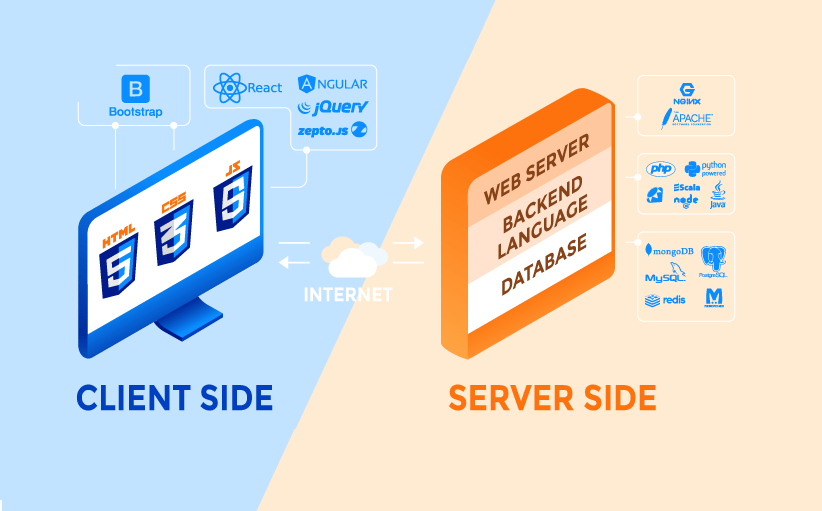
Tecnologie front-end
HTML
L’HTML o Hypertext Markup Language è un popolare linguaggio di markup standard che consente agli sviluppatori di strutturare i contenuti delle pagine web utilizzando una serie di elementi della pagina. Sviluppato da Tim Berners-lee e rilasciato nel 1993, l’HTML si è rapidamente evoluto ed è diventato il linguaggio di markup standard in tutto il mondo. Attualmente è in uso la versione 5.
CSS
I CSS o Cascading Style Sheets sono i cosiddetti fogli di stile, che consentono agli sviluppatori di separare il contenuto e il layout dei siti web sviluppati con linguaggi di markup. Utilizzando i CSS, è possibile definire uno stile per gli elementi e riutilizzarlo più volte. Allo stesso modo, è possibile applicare uno stile a più siti. È un linguaggio semplice e facile da imparare. È possibile applicare uno stile a un singolo elemento, a un’intera pagina web o all’intero sito. È anche compatibile con i dispositivi mobile.
JavaScript
JavaScript o JS è il linguaggio di programmazione lato client più popolare, utilizzato negli ultimi tempi da oltre il 90% dei siti web. È stato progettato da Brendan Eich di Netscape nel 1995. JavaScript utilizza una sintassi semplice e facile da imparare. Il linguaggio è così popolare che ogni browser è dotato di un motore JS per eseguire codice JavaScript sui dispositivi. È facile inserire codice JS in qualsiasi pagina web, il che lo rende altamente interoperabile. Permette di creare interfacce ricche per offrire una migliore esperienza UI/UX. Essendo sul lato client, JS riduce anche il carico del server.
Tuttavia, gli sviluppatori devono prestare attenzione alla sicurezza, poiché il codice viene eseguito lato client e a volte può essere sfruttato dagli hacker.
React
React è un JavaScript open-source che ha guadagnato popolarità negli ultimi anni. È stato sviluppato da Jordan Walke di Facebook nel 2013. I vantaggi di React consistono nel creare facilmente web app dinamiche di alta qualità con un codice e uno sforzo minimi.
ReactJS, infatti, è facile da imparare e da usare. Gli sviluppatori hanno a disposizione un’ampia documentazione e molti strumenti utili. Il codice è riutilizzabile. ReactJS utilizza un DOM virtuale, il che significa che gli elementi interessati vengono aggiornati quando viene apportata una modifica, invece di riscrivere l’intero albero del DOM. Questo migliora l’efficienza e ottimizza l’uso della memoria. ReactJS utilizza un flusso di dati unidirezionale, il che significa che le modifiche apportate agli elementi “figli” non influiscono sull’elemento “genitore”. Il codice è facile da testare e SEO-friendly.
Il lato negativo è che l’ambiente di sviluppo ReactJS è altamente dinamico, il che significa che gli sviluppatori devono monitorare proattivamente i cambiamenti e adattare rapidamente le nuove competenze per sfruttare React. Inoltre, le tecnologie React stanno migliorando rapidamente, ma la documentazione non riesce a tenere il passo. Un’area critica è che ReactJS si concentra sulla parte dell’interfaccia utente ed è necessario dipendere da altre librerie per le funzionalità lato server.
Vue.js
Vue.js è un framework JavaScript open-source scritto da Evan You nel 2014. Questo framework consente agli sviluppatori di costruire facilmente interfacce UI per dispositivi web, desktop e mobili. Vue.js è dotato di strumenti pratici che soddisfano le esigenze di programmazione di base. Lo strumento è leggero da scaricare e da installare. È facile da imparare e da usare. Utilizza un DOM virtuale, in modo che quando l’utente interagisce con un elemento, il browser non debba eseguire il rendering dell’intera pagina, ma solo dell’elemento. La velocità e le prestazioni sono buone. Utilizza un modello di binding dei dati bidirezionale che consente di tenere traccia dei dati e di aggiornare i componenti correlati in modo più efficiente. I componenti sono riutilizzabili. Si integra facilmente con le applicazioni esistenti. La documentazione è concisa e ben strutturata. Il supporto della comunità è buono.
Vue.js è stato ampiamente adattato da aziende cinesi come Alibaba e Xiomi. Per questo motivo, i forum e le discussioni sono spesso in lingua cinese, creando una barriera linguistica per chi parla inglese. Il kit di strumenti è adatto a progetti di base, ma offre un supporto limitato per progetti su larga scala. La flessibilità che offre può creare problemi di qualità anche su progetti di grandi dimensioni. GitLab, Alibaba e Adobe sono alcune delle aziende più famose che utilizzano Vue.js.
Angular.js
Angular è un framework open-source per applicazioni web sviluppato da Google nel 2016. È una riscrittura completa del framework Angular.js. Ad oggi, è uno dei framework di sviluppo front-end più popolari disponibili sul mercato.
NGModules è il nome del blocco di costruzione di Angular, che offre tutte le funzionalità per lo sviluppo di applicazioni come componenti, moduli, template, direttive, iniezioni di servizi e dipendenze, routing ecc. Aiuta gli sviluppatori a costruire rapidamente prototipi. Utilizza semplici modelli HTML. I test sono facili e veloci grazie allo stile dell’architettura a iniezione di dipendenze.
Angular utilizza il binding bidirezionale dei dati, che rende la manipolazione del DOM facile e veloce. Le caratteristiche che migliorano le prestazioni della CPU lo rendono una buona scelta per le web app su larga scala. Viene fornito con vari plugin e strumenti già pronti. Proveniente dal gigante informatico Google, Angular gode di un vivace supporto da parte della comunità. La popolarità e il valore di mercato implicano la presenza sul mercato di professionisti Angular altamente qualificati.
Tuttavia, la struttura gerarchica può talvolta rendere il debug una sfida. Concetti come l’inversione del controllo, la ricerca delle dipendenze e l’iniezione delle dipendenze richiedono una curva di apprendimento ripida. Per eseguire Angular è necessario avere JavaScript installato sulla macchina. Sebbene il binding bidirezionale dei dati sia un’ottima funzionalità, può comportare prestazioni lente su dispositivi vecchi e legacy. Anche l’integrazione dell’infrastruttura legacy con Angular è un problema.
Conclusioni
Tra gli strumenti di sviluppo front-end qui presentati, React e Vue.js sono altamente raccomandati. React è uno strumento leggero e dotato delle migliori funzioni per gli sviluppatori, che consente di creare rapidamente software di qualità.
Vue.js è un prodotto orientato alle viste, leggero, facile da usare e dotato di un potente set di strumenti per gli sviluppatori. Per iniziare, è sufficiente caricare l’interfaccia e aggiungere JavaScript.
Livello di applicazione: Componente lato server (back-end)
Il componente lato server è la componente chiave dell’architettura dell’applicazione web che riceve le richieste degli utenti, esegue la logica aziendale e fornisce i dati richiesti ai sistemi front-end. Contiene server, database, servizi web ecc.
Qui di seguito presentiamo alcune delle tecnologie lato server comunemente utilizzate.
Node.js
Node.js è un ambiente di runtime open-source multipiattaforma sviluppato da Ryan Dahl. È stato costruito su Google Chrome V8 Engine per eseguire applicazioni di rete e lato server ed è stato rilasciato nel 2009. Gli sviluppatori utilizzano JavaScript per creare applicazioni node.js ed eseguirle sul runtime node.js utilizzando le piattaforme Windows, macOS e Linux.
Node.js è molto popolare perché offre una ricca libreria di moduli JavaScript che consentono agli sviluppatori di creare rapidamente applicazioni di qualità. Node.js non bufferizza i dati ed esegue il codice molto velocemente. È guidato dagli eventi e asincrono, viene eseguito su un singolo thread ed è altamente scalabile. Node.js si adatta meglio alle applicazioni con streaming di dati, ad alta intensità di dati, legate all’I/O e basate su JSON-API. Paypal, Uber, eBay e GoDaddy sono alcune delle applicazioni più popolari alimentate da Node.js. Non è adatto alle applicazioni ad alta intensità di CPU.
Java
Java è uno dei linguaggi di programmazione più popolari ed efficaci di tutti i tempi. Scritto da James Gosling nel 1995, Java è un linguaggio di programmazione orientato agli oggetti e basato su classi che consente agli sviluppatori di scrivere codice ed eseguirlo su qualsiasi piattaforma utilizzando l’ambiente della macchina virtuale Java (JVM). Ciò significa che non è necessario disporre di Java sulla macchina di destinazione. Il linguaggio è facile da imparare, codificare, compilare ed eseguire il debug. Essendo indipendente dalla piattaforma, i programmi Java sono economici da costruire ed eseguire. Sfruttando i concetti OOPS, è possibile riutilizzare gli oggetti in altri programmi. Poiché non lavora con puntatori espliciti, evita l’accesso non autorizzato alla memoria. Supporta il multi-threading, la portabilità, la garbage collection automatica, la rete distribuita ecc.
Il lato negativo è che Java richiede uno spazio di memoria significativo. A causa dell’astrazione della JVM, i programmi vengono eseguiti più lentamente. Tuttavia, per lo sviluppo di componenti lato server dell’architettura delle applicazioni web in Java, i vantaggi superano gli svantaggi.
Python
Python è un linguaggio di programmazione di alto livello open-source scritto da Guido Van Rossum e rilasciato nel 1991. Oggi è un linguaggio di programmazione popolare e in rapida crescita e rappresenta una valida alternativa per la costruzione di architetture di applicazioni web in Java. È semplice da imparare e sviluppare e ricco di funzionalità. Questo linguaggio a tipizzazione dinamica è altamente flessibile e adatto a progetti di applicazioni web di piccole e grandi dimensioni, oltre che a una varietà di segmenti come le applicazioni mobili, i videogiochi, la programmazione dell’intelligenza artificiale ecc. Permette di fare di più con meno codice, il che significa che è possibile costruire e testare rapidamente prototipi che aumentano la produttività. Python offre una vasta libreria che contiene codice per quasi tutti i tipi di programmi. Grazie alla sua vivace comunità, il supporto è sempre disponibile.
Tuttavia, rispetto ai linguaggi moderni, Python è più lento. I problemi di threading sono un altro dei punti di debolezza. Python non è nativo per le applicazioni mobili. Google, Spotify, Instagram e Facebook sono alcuni dei colossi informatici che utilizzano Python.
PHP / Laravel
Laravel è un framework PHP che aiuta gli sviluppatori a costruire applicazioni web personalizzate con facilità. È un framework open-source molto popolare tra i vari framework PHP. Laravel è un framework MVC (Model, View, Controller).
La sintassi di Laravel è elegante ed espressiva. Grazie alle numerose funzioni e strutture integrate, gli sviluppatori possono scrivere facilmente il codice e distribuire le applicazioni più velocemente. Migliora le prestazioni e la velocità. La documentazione è buona. Un importante vantaggio di PHP Laravel è la sua funzione di test automatico, che aiuta a testare ed eseguire il debug degli errori nella fase iniziale. Sono disponibili anche attività e pianificazioni automatiche. Il supporto per la mappatura relazionale degli oggetti è elegante. Laravel offre token per la falsificazione delle richieste cross-site che garantiscono la sicurezza. È scalabile e conveniente.
Tuttavia, a volte, gli aggiornamenti del prodotto possono creare problemi. Il Laravel Composer può essere migliorato. Poiché si tratta di un prodotto relativamente nuovo, il supporto della comunità non è così elevato. Laravel è più adatto alle organizzazioni di medie e piccole dimensioni.
Go
Il linguaggio di programmazione Go proviene dal gigante informatico Google, che gli conferisce una notevole forza in primo luogo. È stato scritto da Robert Griesemer, Ken Thompson e Rob Pike nel 2009. Go è noto anche come Golang. È simile al linguaggio C ed è facile da imparare e da costruire. Non essendoci runtime virtuali, il codice Go si compila più velocemente e produce anche file binari più piccoli. Utilizza la tipizzazione statica e i tipi di interfaccia. La libreria standard offre una serie di funzioni integrate e il supporto per i test. È disponibile la garbage collection. La programmazione concorrente è facile rispetto ad altri linguaggi.
L’aspetto negativo è che il supporto non è adeguato. Le interfacce implicite possono essere difficili da gestire. Il riutilizzo del codice non è facile.
.NET
.NET è un framework di sviluppo software sviluppato da Microsoft e rilasciato nel 2001 per applicazioni desktop e web. Nato dal colosso informatico Microsoft, . NET è diventato rapidamente popolare per lo sviluppo di una varietà di prodotti software.
.NET è disponibile in 3 versioni:
- .NET Framework: È il primo prodotto specifico per la piattaforma Windows.
.NET Core: .NET Core è stato rilasciato nel 2016 come soluzione multipiattaforma per adattarsi alle piattaforme macOS e Linux.
- Xamarin: Xamarin non è sviluppato da Microsoft, ma è stato acquisito dall’azienda nel 2016. Xamarin estende la piattaforma .NET per supportare lo sviluppo di applicazioni mobili native.
- .NET Standard è un’unica libreria di classi base per le implementazioni di .NET Framework, .NET Core e Xamarin.
.NET utilizza un modello di programmazione orientata agli oggetti (OOP) e una struttura modulare che consente agli sviluppatori di suddividere il codice in parti più piccole e di costruire e gestire senza problemi i prodotti software utilizzando pipeline CI/CD. Offre un sistema di caching robusto e semplice che migliora la velocità e le prestazioni. Il monitoraggio automatico in ASP.NET è un ulteriore vantaggio. Visual Studio IDE è un IDE che aiuta gli sviluppatori a monitorare e gestire tutte le operazioni di sviluppo da un unico pannello. Essendo indipendente dal linguaggio e dalla piattaforma, consente di utilizzare una varietà di ambienti di sviluppo. Il deployment e la gestione del codice sono flessibili e semplici. .NET è dotato di un’ampia documentazione e del supporto della comunità.
Tuttavia, il supporto relazionale agli oggetti è limitato. La forte dipendenza da Microsoft comporta un vendor lock-in e costi di licenza più elevati. .NET si adatta meglio ai prodotti aziendali che richiedono un’elevata scalabilità e soluzioni multipiattaforma.
Ruby
Ruby è un popolare linguaggio di programmazione sviluppato dal giapponese Yukihiro Matsumoto nel 1995. L’efficienza dei tempi è uno dei maggiori vantaggi di Ruby. In combinazione con il framework Rails, consente agli sviluppatori di creare e distribuire rapidamente le applicazioni. Lo strumento offre un’ampia libreria e strumenti utili. È dotato di sicurezza integrata per mitigare i rischi legati a SQL Injections, Cross-site Scripting Software (XSS) e Cross-site Request Forgery (CSRF). Ruby ha una comunità di supporto e una buona documentazione.
Sebbene gli sviluppatori possano creare rapidamente applicazioni, la velocità delle stesse è un problema. Detto questo, il problema riguarda soprattutto le applicazioni su larga scala. Le organizzazioni di piccole e medie dimensioni non hanno problemi in questo campo.
Ruby non è così popolare come Java o Python. Per questo motivo, non è facile trovare professionisti di qualità per questo segmento. Airbnb, GitHub, Bloomberg ed Etsy sono alcune aziende popolari che utilizzano Ruby.
Tra gli strumenti di sviluppo lato server, Node.js e Python sono altamente raccomandati. Node.js è una soluzione multipiattaforma facile da imparare, leggera, facile da sviluppare, altamente scalabile ed estensibile. Python utilizza una sintassi semplice, si concentra sul linguaggio naturale e facilita la scrittura e l’esecuzione del codice in modo più rapido. La comunità è inoltre molto solidale. Php rimane leader per la numerosità di sviluppatori, framework e popolatità.

Come funzionano le API RESTful
Un’API RESTful scompone una transazione per creare una serie di piccoli moduli. Ogni modulo si occupa di una parte sottostante della transazione. Questa modularità offre agli sviluppatori una grande flessibilità, ma può essere impegnativo per gli sviluppatori progettare la propria API REST da zero. Attualmente, diverse aziende forniscono modelli che gli sviluppatori possono utilizzare; i modelli forniti da Amazon S3, Cloud Data Management Interface (CDMI) e OpenStack Swift sono i più popolari.
Un’API RESTful utilizza comandi per ottenere risorse. Lo stato di una risorsa in un determinato momento è chiamato rappresentazione della risorsa. Un’API RESTful utilizza le metodologie HTTP esistenti definite dal protocollo RFC 2616, quali:
- GET per recuperare una risorsa;
- PUT per modificare lo stato o aggiornare una risorsa, che può essere un oggetto, un file o un blocco;
- POST per creare la risorsa e
- DELETE per rimuoverla.
Con REST, i componenti in rete sono una risorsa a cui l’utente chiede di accedere, come una scatola nera i cui dettagli di implementazione non sono chiari. Tutte le chiamate sono stateless; nulla può essere conservato dal servizio RESTful tra le esecuzioni.
I formati di dati supportati dall’API REST sono:
- applicazione/json
- applicazione/xml
- applicazione/x-wbe+xml
- applicazione/x-www-form-urlencoded
- multipart/form-data
Livello applicazione: Interfaccia di programmazione delle applicazioni (API)
L’API (Application Programming Interface) non è una tecnologia, ma un concetto che consente agli sviluppatori di accedere a determinati dati e funzioni di un software. In parole povere, è un mediatore che permette alle applicazioni di comunicare tra loro. Comprende i protocolli, gli strumenti e le definizioni delle subroutine necessarie per costruire le app.
Ad esempio, quando si accede a un’applicazione, questa chiama un’API per recuperare i dati e le credenziali dell’account. L’applicazione contatterà i server corrispondenti per ricevere queste informazioni e restituire i dati all’applicazione utente. Un’API web è un’API disponibile sul web tramite il protocollo HTTP. Può essere costruita, per esempio, utilizzando tecnologie come .NET e Java.
Con le API, gli sviluppatori non devono creare tutto da zero, ma utilizzare le funzioni esistenti esposte come API per aumentare la produttività e accelerare il time to market. Riducendo gli sforzi di sviluppo, le API riducono significativamente i costi di sviluppo. Inoltre, migliorano la collaborazione e la connettività all’interno dell’ecosistema, migliorando l’esperienza dei clienti.
Esistono diversi tipi di API:
- API RESTful: sono API di trasferimento di stato rappresentativo in formato JSON leggero. Sono altamente scalabili, affidabili e offrono prestazioni rapide, il che le rende le API più popolari ed utilizzati al momento.
- SOAP: Simple Object Access Protocol utilizza XML per la trasmissione dei dati. Richiede una maggiore larghezza di banda e una sicurezza avanzata.
- XML-RPC: Extensible Markup Language – Remote Procedure Calls utilizza un formato XML specifico per la trasmissione dei dati.
- JSON-RPC: utilizza il formato JSON per la trasmissione dei dati.
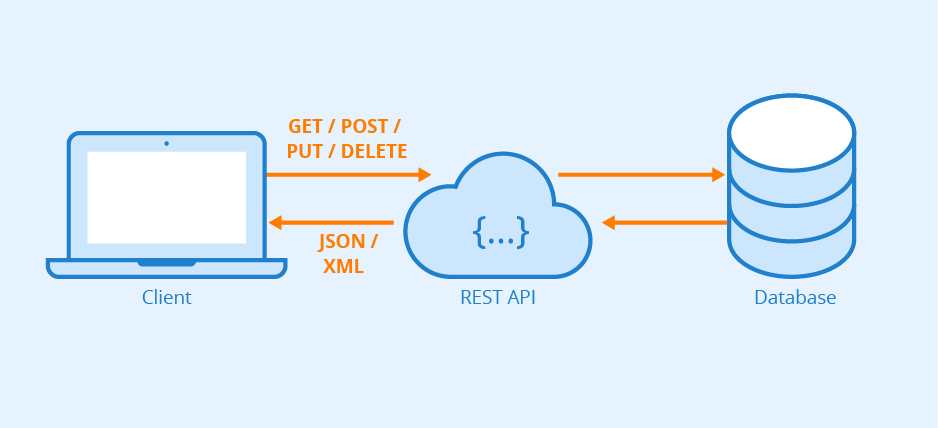
Come funziona SOAP
SOAP utilizza XML come formato di dati per i messaggi inviati e ricevuti da un client API e fornisce quattro dimensioni distinte al protocollo API:
- Envelope: definizione della struttura del messaggio
- Encoding: regole per esprimere il tipo di dati<
- Requests: come è strutturata ogni richiesta API SOAP
- Responses: come è strutturata ogni risposta dell’API SOAP
Anche se SOAP è molto rigoroso nelle sue linee guida di implementazione, è anche noto per essere estensibile. SOAP consente di aumentare la struttura dei messaggi e di evolverli per soddisfare requisiti specifici. Come altri approcci alla fornitura di API, SOAP utilizza HTTP come mezzo di trasporto, ma uno dei suoi punti di forza è che può anche sfruttare SMTP, TCP e UDP per passare i messaggi avanti e indietro. Ciò consente una maggiore flessibilità quando si tratta di spostare dati, contenuti e sistemi multimediali e applicazioni.
Come funzionano le API XML-RPC
RPC, come abbiamo detto, è l’acronimo di Remote Procedure Call. Come indica il nome, si tratta di un meccanismo per chiamare una procedura o una funzione disponibile su un computer remoto. RPC è una tecnologia molto più vecchia del Web.
Di fatto, RPC offre agli sviluppatori un meccanismo per definire interfacce che possono essere richiamate in rete. Queste interfacce possono essere semplici come una singola chiamata di funzione o complesse come una grande API.
XML-RPC è composto da tre parti relativamente piccole:
- Modello di dati XML-RPC: un insieme di tipi da utilizzare per il passaggio di parametri, valori di ritorno e errori (messaggi di errore).
- Strutture di richiesta XML-RPC: una richiesta HTTP POST contenente informazioni sul metodo e sui parametri.
- Strutture di risposta XML-RPC: una risposta HTTP che contiene valori di ritorno o informazioni sugli errori.
Le richieste XML-RPC sono una combinazione di contenuto XML e intestazioni HTTP. Il contenuto XML utilizza la struttura di tipizzazione dei dati per passare i parametri e contiene informazioni aggiuntive che identificano la procedura chiamata, mentre le intestazioni HTTP forniscono un wrapper per passare la richiesta sul Web.
Ogni richiesta contiene un singolo documento XML, il cui elemento principale è un elemento methodCall. Ogni elemento methodCall contiene un elemento methodName e un elemento params. L’elemento methodName identifica il nome della procedura da richiamare, mentre l’elemento params contiene un elenco di parametri e i loro valori. Ogni elemento params comprende un elenco di elementi param, che a loro volta contengono elementi value.
Come funzionano le API JSON-RPC
RPC è l’acronimo di Remote Procedure Call (chiamata di procedura remota) ed è un protocollo che un programma può utilizzare per richiedere un servizio a un programma situato in un altro computer di una rete senza doverne comprendere i dettagli. RPC utilizza il modello client-server. Come una normale chiamata di procedura locale, una RPC è un’operazione sincrona che richiede la sospensione del programma richiedente fino alla restituzione dei risultati della procedura remota. Tuttavia, l’uso di processi leggeri o thread che condividono lo stesso spazio di indirizzamento consente l’esecuzione simultanea di più RPC.
Il concetto di RPC è presente nel mondo dello sviluppo del software da oltre 50 anni, ma nonostante ciò non è ancora così conosciuto come ci si aspetterebbe per un fenomeno così duraturo.
Detto questo, non è poi così sorprendente, se si considera che la maggior parte del software attuale è basato sul web e che REST è stato progettato con una mentalità web-first. Quando REST è nato, le API RPC utilizzavano ancora l’XML e questo era problematico. In XML, molti attributi sono solo stringhe ed è necessario garantire i tipi di dati aggiungendo un livello di metadati che descriva cose come quali campi sono di quale tipo.
Oggi molte piattaforme decentralizzate note utilizzano API basate su JSON-RPC: Ethereum, Ripple e Bitcoin tra le altre.
Livello di applicazione: Istanza server / Istanza cloud
I server o le istanze cloud sono una parte importante dell’architettura di una web application. Un’istanza cloud è un’istanza di server virtuale costruita, fornita e ospitata da un cloud pubblico o privato e accessibile via Internet. Funziona come un server fisico che può spostarsi senza problemi su più dispositivi o distribuire più istanze su un singolo server. Per questo motivo, è altamente dinamico, scalabile e conveniente. È possibile sostituire automaticamente i server senza tempi di inattività delle applicazioni. Utilizzando le istanze cloud, è possibile distribuire e gestire facilmente le applicazioni web in qualsiasi ambiente.
Livello dati: Database
Un database è un componente chiave di una web application che memorizza e gestisce le informazioni per un’applicazione web. Utilizzando una funzione, è possibile cercare, filtrare e ordinare le informazioni in base alle richieste dell’utente e presentare le informazioni richieste all’utente finale. Consentono l’accesso basato sui ruoli per mantenere l’integrità dei dati.
Nella scelta di un database per l’architettura della web app, i quattro aspetti da tenere in considerazione sono la dimensione, la velocità, la scalabilità e la struttura. Per i dati strutturati, i database basati su SQL sono un’ottima scelta.
Per gestire dati non strutturati, NoSQL è una buona opzione. È adatto alle applicazioni in cui la natura dei dati in arrivo non è prevedibile. I database a valore chiave associano ogni valore a una chiave e sono adatti ai database che memorizzano i profili degli utenti, le recensioni, i commenti dei blog, ecc. Per le analisi, i database a colonne larghe sono una buona scelta.
Architettura delle applicazioni web avanzata e scalabile
L’architettura delle web app è in continua evoluzione. Per questo motivo, le aziende devono monitorare proattivamente questi cambiamenti e riallineare l’architettura di conseguenza.
Qui di seguito illustriamo alcune tendenze da tenere sotto controllo:
Sistema di caching
Il sistema di caching è un archivio di dati locale che facilita l’accesso rapido ai dati per un server applicativo, invece di contattare ogni volta il database. In una configurazione tradizionale, i dati sono memorizzati in un database. Quando un utente fa una richiesta, il server dell’applicazione richiede i dati dal database e li presenta all’utente. Quando gli stessi dati vengono richiesti di nuovo, il server deve eseguire nuovamente lo stesso processo, che è ripetitivo e richiede molto tempo. Memorizzando queste informazioni in una memoria cache temporanea, le app possono presentare rapidamente i dati agli utenti.
Il sistema di cache può essere progettato in 4 modelli:
- Application Server Cache: cache in memoria accanto al server dell’applicazione (per le applicazioni che hanno un singolo nodo).
- Cache globale: tutti i nodi accedono ad un singolo spazio di cache
- Cache distribuita: la cache è distribuita tra i nodi e viene utilizzata una funzione di hashing coerente per indirizzare la richiesta ai dati richiesti.
- Content Delivery Network (CDN): viene utilizzata per fornire grandi quantità di dati statici.
Strumenti di caching
Redis e Memcached sono i due sistemi di caching più popolari con caratteristiche simili. Tuttavia, Redis offre una ricca serie di strumenti che lo rendono applicabile per l’esecuzione di una varietà di compiti. D’altra parte, Memcached è semplice e facile da usare.
Il sistema di caching di AWS si chiama AWS ElastiCache. Questo servizio web consente agli amministratori di scalare e gestire un servizio di archiviazione dati in-memory nel cloud. AWS offre anche un data store in-memory completamente gestito compatibile con Redis, chiamato Amazon ElastiCache for Redis, e un servizio di data store in-memory completamente gestito compatibile con Memcached, chiamato Amazon ElastiCache for Memcached.
Archiviazione nel cloud (Amazon S3)
Nell’architettura di una web app, il cloud storage è un requisito oramai dato per scontato. Il cloud storage consiste nell’archiviare i dati nel cloud e nell’accedervi tramite Internet.
Un fornitore di servizi cloud fornisce l’infrastruttura di archiviazione secondo un modello di abbonamento pay-per-use.
Poiché AWS è il fornitore di servizi cloud più popolare, Amazon S3 è la soluzione di archiviazione cloud più utilizzata negli ambienti di architettura di applicazioni web AWS in tutto il mondo. Amazon Simple Storage Service (S3) è un servizio di cloud storage flessibile, economico, duraturo, sicuro e in grado di offrire elevata disponibilità e scalabilità.
In AWS, un’unità di cloud storage è chiamata “bucket”, in cui vengono memorizzati gli oggetti. Quando si crea un bucket, questo viene distribuito nella regione specificata dall’utente. Una volta terminato il deployment e aggiunti gli oggetti al bucket, l’utente può scegliere il tipo di classe di archiviazione insieme a funzioni quali il controllo delle versioni, i criteri del ciclo di vita, i criteri del bucket, ecc. AWS si occupa della gestione del ciclo di vita di un gruppo di oggetti, compresi i criteri IAM e la protezione dei dati.
Azure Cloud Storage è un altro popolare servizio di cloud storage offerto da Microsoft Azure. L’aspetto migliore di Azure Storage è l’alta disponibilità del 99,95% di uptime e l’elevata sicurezza. Con un prezzo di 0,18 dollari per GB/mese, è altamente conveniente. Azure è dotato di una serie completa di strumenti per l’accesso amministrativo e per gli sviluppatori che aiutano le organizzazioni a coordinare senza problemi l’intera attività aziendale.
Google Cloud Storage è l’offerta di cloud storage di Google con un prezzo a partire da 0,02 dollari per GB al mese. È disponibile in più regioni, offre un’elevata durata e si integra facilmente con altri servizi Google. Lo strumento è dotato di una buona documentazione.
CDN (CloudFront)
Una Content Delivery Network (CDN) è una rete di server installati in varie località per fornire contenuti più velocemente e meglio agli utenti. Invece di contattare il server centrale, la richiesta dell’utente viene indirizzata a un server CDN che memorizza una versione in cache del contenuto. In questo modo, la velocità e le prestazioni del sito aumentano e la perdita di pacchetti diminuisce. Il carico del server diminuisce. Inoltre, consente la segmentazione del pubblico e una sicurezza web avanzata.
CloudFront è un popolare servizio CDN per l’architettura delle applicazioni web AWS. Agisce come una cache distribuita per offrire maggiore velocità, bassa latenza e una migliore esperienza del cliente. Considerando la presenza globale di AWS, CloudFront offre una gamma più ampia di posizioni geografiche per gli utenti. CloudFront si integra bene con altri servizi AWS come Amazon EC2, AWS Lambda, Amazon CloudWatch, Amazon S3, ecc. per semplificare il lavoro. È flessibile, facile da configurare e offre un’elevata scalabilità. Dispone inoltre di servizi elastici e di analisi. È inoltre possibile controllare l’accesso ai contenuti.
Azure CDN è una famosa rete di distribuzione dei contenuti della piattaforma cloud Microsoft Azure, facile da configurare e utilizzare e con una bassa latenza.
La rete di distribuzione dei contenuti di Google si chiama Cloud CDN. Sfrutta i server edge distribuiti a livello globale per memorizzare nella cache i contenuti nel luogo di utilizzo e distribuirli ad alta velocità.
CloudFlare è un altro servizio CDN molto diffuso. Sebbene CloudFlare offra principalmente solidi servizi DNS e non sia una rete di distribuzione dei contenuti tradizionale, agisce come reverse proxy per instradare il traffico attraverso la sua rete globale di centri dati.
Load balancer
Come dice il nome, il load balancer è un servizio che bilancia i carichi di traffico distribuendoli su diversi server in base alla disponibilità o a criteri predefiniti. Quando una richiesta dell’utente viene ricevuta dal load balancer, questo recupera lo stato di salute del server in termini di disponibilità e scalabilità e instrada la richiesta verso il server migliore. Un bilanciatore di carico può essere un componente hardware o un programma software.
Il bilanciamento del carico può essere effettuato in due modi:
- Bilanciamento del carico a livello TCP/IP: bilanciamento del carico basato sul DNS
- Bilanciamento del carico a livello di applicazione
Strumenti di bilanciamento del carico
Il bilanciatore di carico elastico originale di AWS si chiama AWS Classic Load Balancer. Funziona a livello TCP (Layer 4) e a livello di applicazione (Layer 7). Tuttavia, inoltra il traffico solo su una porta per istanza.
Un altro importante LB è AWS Application Load Balancer, che funziona a livello di applicazione (HTTP) e può inoltrare il traffico su più porte per istanza. Inoltre, serve più nomi di dominio.
Server multipli
In un’architettura web tradizionale, sono presenti un server web e un database. Il server web ascolta le richieste dei client e contatta il database per fornire le informazioni richieste o elaborare la logica aziendale. Quando gli utenti contemporanei aumentano, il server web esaurisce le risorse. Anche se l’aggiornamento della configurazione del server è utile per un po’ di tempo, fornisce capacità limitate e causa un singolo punto di guasto. La distribuzione su più server è una buona scelta per creare un’architettura web altamente scalabile.
Nel progettare una architettura multi-server, le organizzazioni possono collegare più server di distribuzione del sistema operativo a un unico database o a più database. Tuttavia, è importante mantenerli replicati con contenuti appropriati. La replica può essere programmata a orari specifici.
Message Queues
Una coda di messaggi è un buffer che memorizza i messaggi in modo asincrono e facilita la comunicazione tra i diversi servizi di una web application. Nell’attuale ambiente dei microservizi, il software viene sviluppato in blocchi più piccoli, modulari e indipendenti che comunicano tra loro utilizzando API RESTful. La comunicazione tra questi blocchi è coordinata mediante code di messaggi. I componenti software si collegano alle estremità di queste code di messaggi per inviare e ricevere messaggi ed elaborarli. Le code di messaggi offrono una scalabilità granulare, semplificano il disaccoppiamento dei processi e aumentano l’affidabilità e le prestazioni.
Amazon Simple Queue Service (SQS) è un servizio di code di messaggistica publish/subscribe (pub/sub) completamente gestito e offerto da Amazon. Utilizzando l’API dei servizi web fornita da AWS SQS, gli utenti possono accedere ai messaggi tramite qualsiasi linguaggio di programmazione. La messaggistica viene elaborata in modo asincrono, il che significa che i messaggi attendono in una coda e le applicazioni possono accedervi in un secondo momento.
Amazon SQS utilizza due tipi di coda:
- First-in First-Out (FIFO): le stringhe di messaggi vengono elaborate nello stesso ordine di invio. È utile per le operazioni in cui l’ordine di elaborazione è critico.
- Code standard: la stringa di messaggi rimane la stessa, ma l’ordine può cambiare. È utile per le operazioni in cui i messaggi sono distribuiti a vari nodi.
AWS SQS supporta 300 messaggi al secondo. Ogni messaggio può essere personalizzato. È possibile conservare i messaggi per periodi prolungati compresi tra 1 minuto e 14 giorni. La capacità di disaccoppiare i componenti della web application aiuta a ottenere prestazioni elevate. Elimina le spese amministrative, mantenendo i dati sensibili. La compatibilità con altri prodotti AWS consente di integrarlo facilmente con l’infrastruttura esistente.
Architettura e diagrammi della web application
Diagramma dell’architettura della web app
Con l’aiuto di un diagramma dell’architettura della web app, è possibile analizzare un processo dall’inizio alla fine. È importante considerare gli elementi e le risorse che intervengono nel flusso, come le API, il cloud storage, le tecnologie e i database.
L’architettura delle applicazioni web può essere classificata in diverse categorie in base ai modelli di sviluppo e distribuzione del software.
Architettura monolitica
L’architettura monolitica è un modello tradizionale di sviluppo del software, noto anche come architettura di sviluppo web, in cui l’intero software viene sviluppato come un unico pezzo di codice attraverso il tradizionale modello a cascata. Ciò significa che tutti i componenti sono interdipendenti e interconnessi e ogni componente è necessario per far funzionare l’applicazione. Per modificare o aggiornare una specifica funzionalità, è necessario modificare l’intero codice da riscrivere e compilare.
Poiché l’architettura monolitica tratta l’intero codice come un singolo programma, la creazione di un nuovo progetto, l’applicazione di framework, script e template e il test diventano semplici e facili. Anche il deployment è semplice. Tuttavia, quando il codice diventa più grande, diventa difficile gestirlo o fare aggiornamenti; anche per una piccola modifica, è necessario passare attraverso l’intero processo dell’architettura di sviluppo web. Poiché ogni elemento è interdipendente, non è facile scalare l’applicazione. Inoltre, non è affidabile, poiché un singolo punto di guasto può far crollare l’applicazione.
Quando si vuole costruire un’applicazione leggera e si dispone di un budget limitato, l’architettura monolitica serve allo scopo. Una delle ragioni per cui ha senso utilizzare un modello monolitico è quando il team di sviluppo lavora da un’unica sede e non è distribuito in remoto.
Architettura a microservizi
L’architettura a microservizi risolve diverse sfide che si incontrano in un ambiente monolitico. In un’architettura a microservizi, il codice viene sviluppato come servizi indipendenti ad accoppiamento libero che comunicano tramite API RESTful. Ogni microservizio contiene il proprio database e gestisce una logica aziendale specifica, il che significa che è possibile sviluppare e distribuire servizi indipendenti con facilità.
L’architettura a microservizi, essendo liberamente accoppiata, offre la flessibilità necessaria per aggiornare/modificare e scalare i servizi indipendenti. Lo sviluppo diventa facile ed efficiente e la consegna continua è abilitata. Gli sviluppatori possono adattarsi rapidamente alle innovazioni. Per applicazioni altamente scalabili e complesse, i microservizi sono una buona scelta.
Tuttavia, la distribuzione di più servizi con istanze di runtime rimane una sfida. Quando il numero di servizi cresce, cresce anche la complessità della loro gestione. Inoltre, le applicazioni a microservizi condividono database di partizione. Ciò significa che è necessario garantire la coerenza tra più database interessati dalla transazione.
Containers
La tecnologia dei container è l’opzione migliore quando si tratta di distribuire microservizi. Un container è un incapsulamento di un ambiente di runtime leggero per un’applicazione che può essere eseguito su una macchina fisica o virtuale. In questo modo, le applicazioni vengono eseguite in un ambiente coerente, dal dispositivo dello sviluppatore all’ambiente di produzione. Astraendo l’esecuzione a livello di sistema operativo, la containerizzazione consente di eseguire più container all’interno di una singola istanza del sistema operativo. Se da un lato riduce l’overhead e la potenza di elaborazione, dall’altro aumenta l’efficienza.
La containerizzazione consente agli sviluppatori di aggiungere più componenti di app in un unico ambiente VM, invece di segregare il codice in diverse VM, ottenendo così una maggiore potenza di elaborazione dell’applicazione. Grazie alla sua natura leggera, i container vengono eseguiti più rapidamente. Sono flessibili, affidabili e si adattano meglio agli ambienti di microservizi basati su policy.
Docker è la tecnologia di containerizzazione più diffusa che offre un ecosistema completo per le tecnologie di containerizzazione. Offre maggiori prestazioni, una tecnologia facile da usare e un ampio supporto da parte della comunità.
Architettura serverless
L’architettura serverless è un modello di sviluppo di applicazioni software. In questa struttura il provisioning dell’infrastruttura sottostante è gestito da un fornitore di servizi infrastrutturali. Ciò significa che si paga l’infrastruttura solo quando è in uso e non per il tempo di CPU inattivo o lo spazio inutilizzato. L’informatica senza server riduce i costi poiché le risorse vengono utilizzate solo quando l’applicazione è in esecuzione. Le attività di scaling sono gestite dal cloud provider. Inoltre, il codice di backend viene semplificato. Si riducono gli sforzi di sviluppo, i costi e si accelera il time to market.
L’elaborazione multimediale, il live streaming, i chat bot CI Pipeline, i messaggi dei sensori IoT, ecc. sono alcuni dei casi d’uso del serverless computing.
In un’architettura a microservizi, è possibile eseguire l’elaborazione serverless utilizzando AWS Lambda, API Gateway e API Step Functions.
AWS Lambda
AWS Lambda è un servizio di serverless computing offerto da Amazon. Lanciato nel 2014, Lambda offre un ambiente di esecuzione per funzioni scritte in linguaggi come Python, C#, Java, Node.js ecc. Fornisce e rimuove automaticamente i server in base ai requisiti di traffico. Non è necessario caricare l’intera applicazione, ma solo le funzioni necessarie, quindi attivarle per eseguire il servizio. Lambda offre facilità di esecuzione, maggiore resilienza delle app e una soluzione economica. Il lato negativo è che non c’è controllo sull’ambiente.
Gateway API
Un gateway API è uno strumento di gestione delle API che consente di creare, pubblicare, proteggere e gestire API HTTP, WebSocket e REST. Agendo come un reverse proxy, un gateway API riceve varie chiamate API, esegue l’aggregazione dei servizi per soddisfare tali chiamate e fornisce il risultato. I gateway API aiutano a proteggere le API, a eseguire strumenti di analisi sulle API, a collegare un servizio di fatturazione o a gestire le API più vecchie e cancellate, ecc. In un ambiente serverless, le risorse vengono fornite in base alle chiamate API. Il gateway API aiuta a distribuire e gestire le funzioni serverless.
Funzioni AWS Step
AWS Step Functions è uno strumento di workflow visivo di AWS che consente agli sviluppatori di suddividere un processo in una serie di fasi. L’automazione dei processi IT, la creazione di app distribuite e di pipeline di apprendimento automatico diventano facili con questo servizio low-code. È possibile creare e distribuire rapidamente applicazioni affidabili e altamente scalabili e gestire flussi di lavoro stateful e fault-tolerant con meno codice di integrazione.
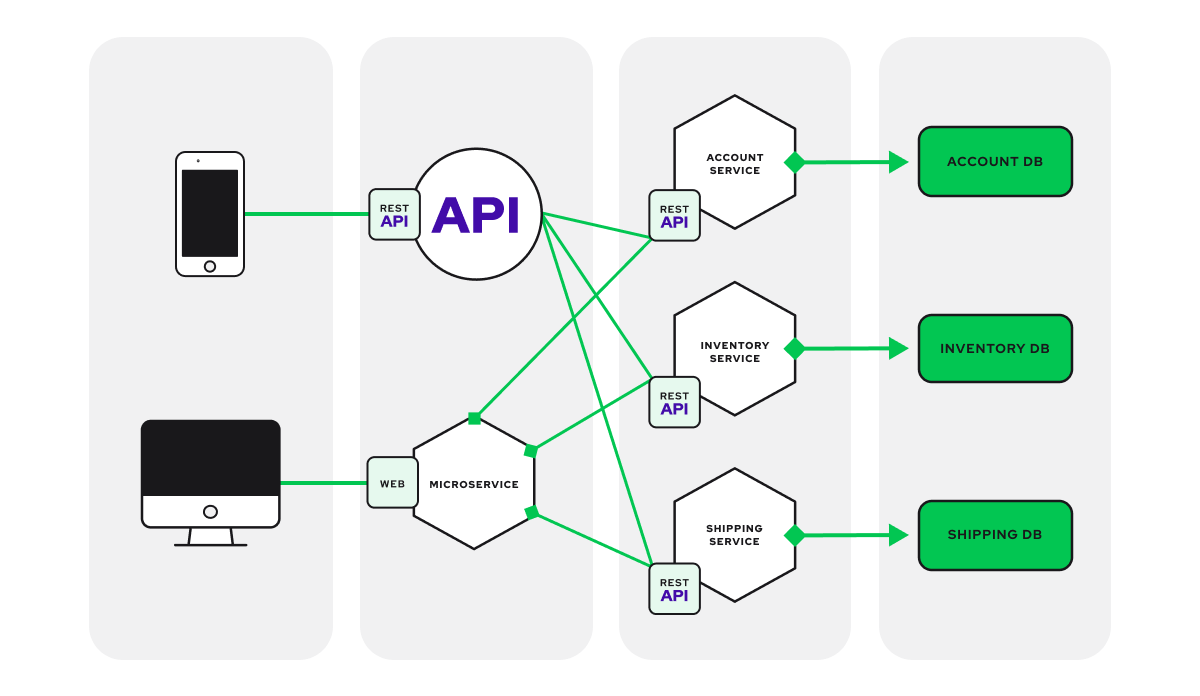
Le best practice per l’architettura delle Web Application
Ecco alcune delle migliori pratiche da seguire per progettare un’ottima architettura di una web application.
Server web scalabile
Un server web scalabile è fondamentale per garantire prestazioni costanti dell’applicazione indipendentemente dal numero di utenti contemporanei, dalla posizione e dall’ora. Esistono tre tipi di opzioni di scalabilità: scalabilità orizzontale, scalabilità verticale e scalabilità diagonale. Mentre il vertical scaling consiste nell’aggiornare/ridimensionare la configurazione del dispositivo, l’horizontal scaling consiste nell’aumentare/diminuire il numero di dispositivi. Lo scaling diagonale consiste nel combinare entrambi i modelli. È consigliabile scegliere un modello di scaling orizzontale, in quanto non si è limitati dalla configurazione o dal numero di server. Inoltre, è possibile combinare lo scaling verticale se e dove possibile.
Adattare il cloud con un’infrastruttura elastica
Con la crescente diffusione di ambienti ibridi e multi-cloud, l’adattamento al cloud e il provisioning proattivo delle risorse sono fondamentali per fornire applicazioni web ad alte prestazioni. L’infrastruttura elastica viene fornita con sistemi di rete preconfigurati, server VM, risorse di storage e di calcolo, consentendo di gestire facilmente l’ambiente con portali self-service. Questo offre la flessibilità necessaria per adattarsi rapidamente alle mutevoli esigenze del mercato e alle aspettative dei clienti.
Infrastruttura immutabile
In poche parole, l’infrastruttura immutabile è qualcosa che non può essere modificato una volta distribuito. Consente agli amministratori di effettuare il provisioning automatico delle risorse utilizzando il codice. Quando i server devono essere aggiornati o modificati, vengono automaticamente sostituiti con altri più recenti.
La deriva configurativa è una grande sfida per le infrastrutture mutabili. I problemi di scalabilità e di debugging durante la replica dell’ambiente di produzione sono un’ulteriore sfida. L’infrastruttura immutabile utilizza un’immagine convalidata e controllata dalla versione per eseguire il provisioning di nuovi server per ogni distribuzione. Pertanto, lo stato precedente del server non è un problema. È possibile testare i server prima di distribuirli. Elimina le derive configurative, consente lo scaling orizzontale e offre un semplice rollback e ripristino con ambienti di staging coerenti.
Approccio a microservizi e serverless
Il microservice e il serverless computing sono entrambi fondamentali per lo sviluppo di applicazioni web. Tuttavia, la differenza è che l’architettura a microservizi offre una soluzione a lungo termine con un’elevata scalabilità, mentre l’informatica serverless offre efficienza del codice. Le funzioni serverless vengono eseguite solo quando vengono attivate.
Combinando entrambi i modelli, è possibile ottenere il meglio di entrambi i mondi. È possibile utilizzare AWS Step Functions per assegnare trigger per combinare diverse funzioni in un servizio e assegnare loro dei trigger. Con i microservizi attivati dagli eventi, è possibile costruire un sistema combinato per ottenere efficienza del codice, stabilità a lungo termine, economicità e scalabilità.
Architettura multi-tenant
Le applicazioni Web vengono ora fornite come applicazioni SaaS. Esistono due modelli di distribuzione delle applicazioni SaaS: l’architettura single tenant e quella multi tenant:
Architettura single-tenant: per ogni organizzazione viene creato un singolo ambiente autonomo che comprende l’infrastruttura, il software e l’ecosistema hardware.
Architettura multi-tenant: un singolo ambiente cloud con servizi completamente centralizzati e logicamente isolati viene condiviso da più organizzazioni.
Per le applicazioni web, l’utilizzo di un’architettura multi-tenant offre molteplici vantaggi. Le organizzazioni possono gestire un’unica base di codice per tutti gli utenti, riducendo le spese generali e i problemi di conflitto di codice. Inoltre, riduce i costi dell’infrastruttura server grazie alle economie di scala. Oltre a ridurre gli sforzi di sviluppo, si ottiene anche un time to market più rapido.
Python/Node.js + React + AWS è la nuova tendenza nella creazione di applicazioni web SaaS.
Proteggere l’architettura con le linee guida HIPAA, PCI e SOC2
Costruire un’architettura sicura è un requisito minimo per qualsiasi organizzazione. L’applicazione di protocolli e politiche di sicurezza non solo protegge i dati e l’ambiente, ma aiuta anche a gestire facilmente le attività di audit e a rispettare le normative governative.
HIPAA: L’Health Insurance Portability and Accountability Act (HIPAA) è un requisito importante che le organizzazioni sanitarie devono rispettare. Aiuta a ridurre le frodi sanitarie e a proteggere le informazioni sanitarie private.
PCI DSS: il Payment Card Industry Data Security Standard (PCI DSS) definisce una serie di procedure e politiche per le organizzazioni finanziarie che trattano dati finanziari sensibili dei clienti.
SOC 2: la procedura di verifica SOC 2 è un aspetto fondamentale per garantire che i dati siano gestiti in modo sicuro dal fornitore di servizi cloud. Anche se le organizzazioni non sono obbligate a rispettare le linee guida SOC 2, è bene seguirle per proteggere i dati dei clienti. Le linee guida SOC 2 definiscono i cinque principi del servizio fiduciario su cui si basa la gestione dei dati dei clienti.
- Disponibilità
- Sicurezza
- Integrità dell’elaborazione
- Riservatezza
- Condifenzialità
Automatizzare le distribuzioni di codice in un ambiente DevOps CI/CD
L’automazione del deployment consiste nell’automatizzare il processo di spostamento del codice tra gli ambienti di test e di produzione. Consente agli sviluppatori di distribuire rapidamente e frequentemente il codice in produzione senza l’intervento umano. AWS offre un servizio di distribuzione completamente gestito sotto forma di AWS CodeDeploy.
Consente di distribuire automaticamente il codice in una serie di ambienti come AWS Lambda, AWS Fargate, Amazon EC2 o on-premise.
L’automazione del deployment fa parte della pipeline DevOps Continuous Integration / Continuous Deployment. Si compone di tre fasi importanti: creazione, test e distribuzione. Quando il codice viene scritto, viene automaticamente testato e aggiunto al repository centrale. Le modifiche vengono convalidate e aggiunte all’applicazione. L’automazione dei test esegue una serie di test a diversi livelli per garantire che il codice sia privo di errori. Quindi il codice viene automaticamente distribuito in produzione.
Costruire l'architettura web con gli strumenti Infrastructure as Code
Infrastructure as Code (IaC) è un metodo per il provisioning automatico dell’infrastruttura utilizzando il codice. Consente di trattare server, rete, database e altre risorse IT come software e di gestirli tramite file di configurazione. In questo modo, è possibile attivare istantaneamente le risorse su richiesta, gestire la coerenza della configurazione, eliminare le derive della configurazione e aumentare l’efficienza dello sviluppo del software. Inoltre, riduce i costi di sviluppo del software. Terraform e AWS CloudFormation sono i due strumenti Iac più diffusi.
Conclusione
Nel mondo del software altamente competitivo di oggi, la creazione di prodotti e servizi di qualità non è sufficiente per ottenere la fiducia dei clienti. Il modo in cui si forniscono i prodotti e i servizi ai clienti è quello che conta di più. Le web app aiutano a farlo. Per questo motivo, le aziende devono creare e distribuire applicazioni web altamente ottimizzate, in grado di offrire ai clienti velocità e prestazioni e un’esperienza UI/UX superiore.
La progettazione della giusta architettura delle applicazioni web è fondamentale.
Digital Stuff è pronta alla sfida ed è sempre disponibile per realizzare nuovi progetti.
FAQ sull’architettura delle web app
Quali sono i modelli comunemente utilizzati per i componenti delle web app?
È necessario scegliere il modello delle applicazioni web in base al numero di database e server utilizzati nell’applicazione. I modelli più diffusi sono tre:
- Un database e un server web
- Un database e più server web
- Più database e più server web
Qual è la differenza tra Architettura delle Web App e Progettazione delle Web App?
L’architettura della web app parla dei componenti di alto livello dell’applicazione e di come interagiscono tra loro, mentre la progettazione della web app parla della progettazione a livello di codice e di come ogni servizio o funzione interagisce con gli altri componenti dell’applicazione.
Che cos’è l’architettura MVC?
MVC è l’acronimo di Model-View-Controller. L’architettura MVC divide la logica dell’applicazione in tre componenti in base alla funzionalità.
Modello: Modello di memorizzazione dei dati
Vista: Componenti che l’utente può visualizzare
Controller: componente intermedio tra il modello e i componenti della vista